 Articles
ArticlesDB - StrataCode persistence
Java supports many ways to connect to a database: JPA, Hibernate, IBatis, and plain JDBC are a few I've used. There's no perfect solution unfortunately as each one is lacking flexibility, performance, and ease-of-use features. It's the so-called impedance mismatch and the solution is to reduce resistance using code-processing, parsing and generating both the database and code formats at the same step, then managing the full-lifecycle as the schema changes.
This allows the best aspects of simple ORM-style code modelling for simple problems, to full-on custom SQL tables and stored procedures for the problems that need it and a smooth transition from one design strategy to the other supporting the same API contracts. Layers support customization of a SQL based model with code, adding fields, queries etc. for specific configurations.
Data binding rules can be used seamlessly in database queries. A simpler API provides thread-safe persistent objects, more efficient caching while still preserving transactional semantics.
Database schema definition
The object/relational mapping problem is perhaps best viewed as a synchronization problem - mapping the tables to classes and back again. There's no right answer of the "SQL-first" versus "code first" debate. Both are supported workflows with DB and you can even modify a hand-written schema by modifying the class to add new persistent tables, fields, and queries.
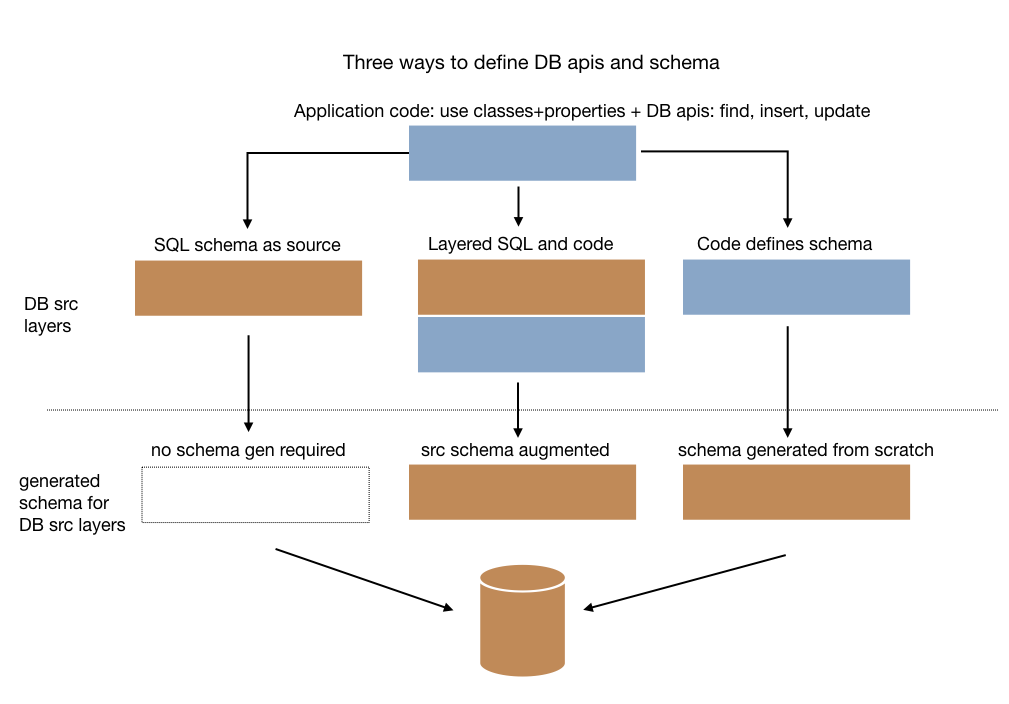
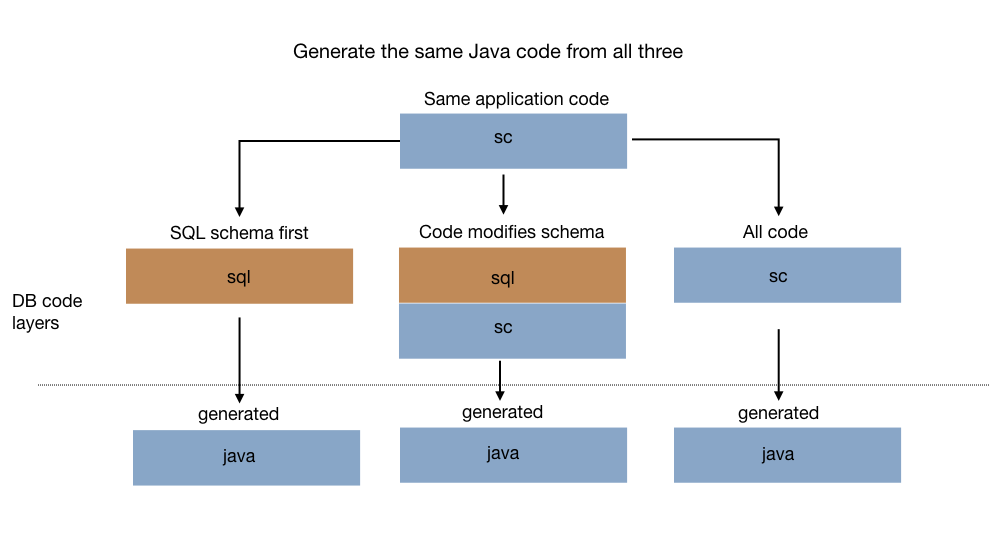
For SQL-first types, the DDL is parsed and produces a SQLFileModel with the list of SQLCommands, especially CreateTable. During code-processing, it converts the CreateTable objects into DBTypeDescriptors containing TableDescriptors and DBPropertyDescriptors.
For code-first types, the DBTypeSettings and DBPropertySettings annotations are used to mark classes that generate definitions of DBTypeDescriptors.
During code-processing, the new or changed DBTypeDescriptors are converted to SQLFileModels and saved as the DDL to use for this application.
Using this design, framework layers can provide well-designed, comprehensive SQL that can be customized by adding columns, aux-tables, queries, and more all with static typing and IDE tools.
Performance, and ease of use
Most Java persistence libraries are stateless and expose the raw data and transactions from JDBC, or support non-threadsafe apis to access instances. To reuse an instance from one transaction to the next, it must be manually detached and re-attached. The APIs are not forgiving or easy to use to say the least.
When caching or multi-threaded access to state is needed, stateless libraries don't help at all. ORM systems usually offer support for "2nd level" caching that's easy to enable, but cached objects are still deserialized for each transaction resulting in overhead that's substantial for data heavy, read-only applications an important case to optimize.
Neither approach is well suited to building easy to configure declarative persistence applications. Both require the application code to manage the transactions and object instances explicitly and ensure single-thread access. Domain model logic becomes split up across the application and database making it harder to reuse and refactor.
For efficient declarative persistence, DB objects are stored using the highlander principle (from the old TV show): "there can be only one" instance for each id. Each instance provides a thread-safe, transactional API to the object and it's properties. Read/write access can use various isolation levels or do locking at a higher level declaratively. Importantly, read-only instances can be safely and efficiently shared between threads.
The API still preserves transaction isolation when required. By default, it supported a read-committed style. While a thread is running any changes it makes are placed in thread-local storage for that object. Once the DB commits the changes, the property values visible to other threads are updated. A transaction can also snapshot values it accesses to ensure they remain consistent for the duration of the transaction, even after another transaction commits.
Like many systems, it supports an automatically managed version property to prevent stale writes for "optimistic concurrency". This approach is important to use for client/server applications since the read and writes typically happen in separate transactions.
Relationship/associations
All persistence frameworks support some way to relate database objects - sometimes called relationships, other times associations.
Typical ORM frameworks are implemented outside of the language - using annotations, byte-code enhancement and ultimately with limited awareness and control over the code and the schema.
The DB framework however uses code processing and is aware of and can control anything about the resulting code and the schema. For example, it uses the type system to differentiate between many-to-many and one-to-many relationships. It converts fields to getX/setX methods automatically, injects apis calls into each and includes any required sendEvent calls to make the operation declarative, and seamless. Data binding is used to support automatic bi-directional relationships.
Properties can be stored in the database by serializing an object or value into JSON when that makes the most sense, e.g. a small array of strings or a value object that makes more sense with a dynamic schema.
More declarative queries with @FindBy
An overarching goal in StrataCode is to move rule-oriented logic into declarative data binding expressions, so that application code is readable and more customizable by declarative programmers. This concept is extended using FindBy queries.
Use the @FindBy annotation on a property to create a static method called: findByPropertyName that retrieves one or more instances of that type using values of that property in the where clause. Use 'with' to provide a list of additional required properties in the where clause and use 'options' to provide a set of properties to optionally include.
for example:
static UserProfile findByEmailAddress(String email, String password) { ... }
When a property's value is defined using a data binding expression, not stored directly in the database, the binding expression is converted to logic in the where clause. For example, to define a bit mask in the DB for efficiency, but expose boolean properties in the API use:
long userPrivMask = 0;
@FindBy
boolean registeredUser :=: (userPrivMask & 1) != 0;
When 'registeredUser' is set, the binding rule converts that to set the '1' bit. When 'registeredUser' is used in a query, it includes the rule userPrivMask & 1 != 0 in the query.
If "a.b" properties are used in @FindBy annotations, when 'b' has it's own table, DB performs the join. If 'b' is stored in JSON, a JSON operator is used in the where clause.
Easy to use apis
All objects with the @DBTypeSettings annotation automatically implement the IDBObject interface and can access an underlying DBObject to store transactional state. The IDBObject interface provides dbInsert(queued=t/f), dbUpdate(), and dbDelete(queued=t/f) methods. To insert a new instance, construct an object instance as normal, set all required properties and call dbInsert(false). Pass true to queue this operation to be committed with the current transaction. The id property is added to the model class if one is not specified with @IdSettings.
Each class defines a DBTypeDescriptor instance to use for accessing information about the type or running persistent methods. This includes declarative queries, persistent properties, etc. There are also methods to find instances using a combination of properties, with sorting, and paging. The programming model becomes much easier to use due to the "only one instance" design.
Custom queries, stored procedures
For when declarative queries are not suitable, it often makes sense to write SQL code directly. With the PostgreSQL parser, DB finds these functions and generates the suitable API to invoke it.
Or annotate a class with a snippet of SQL or provide the name of a resource of SQL to append/or replace previous definitions.
Efficient queries
Properties can be marked as 'onDemand', in which case their value is retrieved the first time they are fetched. When they are not on-demand, single-valued reference properties can be fetched in the same query using an outer join.
A selectGroup can be set on one or more properties to control the set of values retrieved for a given query. By default, the selectGroup name for a property is the table name it's stored in.
The first time a non-fetched query is access, it's fetched from the database. In a multi-threaded context, each query will only - other threads will wait for the result of the first query if they try to fetch it at the same time.
Inheritance
The DB framework provides two ways to use inherited classes. When a base class does not have the @DBTypeSettings annotation - i.e. is not stored in its own table, those properties are added to the table of the first type in the chain which does have @DBTypeSettings. This is for utilities and behavior shared by sub-types but not useful for a primary way of organizing them.
When extending a base type that does have @DBTypeSettings, by default properties of the sub-type are also placed into the table with the base-type. A dbtypeid column is added to the schema. For this mode, all concrete classes must define a typeId value in their @DBTypeSettings to a unique integer value. This value is stored in the schema so it's important to manage those values properly over the lifetime of a database. The sub-type can also store its own properties in a new table that is local to that type. When querying against any type in the type hierarchy, the results will return a mix of that type and all of it's sub-types.
Schema management
DB supports full lifecycle management of schemas. It detects when a schema has changed and launches a command line wizard. It shows the new schema, and the old and consults the current database metadata as a second compatibility check. An alter script generated when one is required to upgrade a schema. The schema manager keeps track of the history of deployed schemas as well.
JSON properties
Some properties make sense to store in JSON, not as a separate table. For any persistent property that is not itself a DB type, it's stored as a JSON property using a JSON serializer that stores the state of each property.
The query engine can translate data binding or findBy queries so they work the same, even if less efficiently using the JSON facilities of the SQL database.
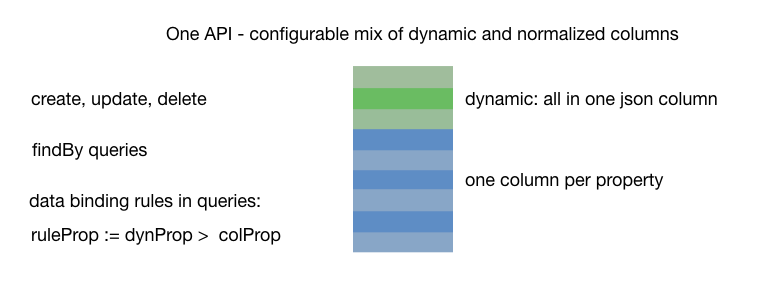
Dynamic columns
To avoid schema changes, set @DBTypeSettings(defaultDynColumn) to have properties in the class stored in a json column in the primary table. For one at a time, use @DBPropertySettings(dynColumn).
The DB layer supports findBy queries on these dynamic properties, and data binding expressions.
Enum columms
Either generate Postgresql enums from Java enums, or use the Java enum's integer value in the DB.
Mixing data sources
Each class can be assembled from more than one data source - perhaps a mix of in-memory data, data in a Postgresql DB, data in a NoSQL store, and a secrets DB. The application code can largely be unaware of how the properties are stored. Layers allow the movement of a property from one data store to another through a configuration change.
There is always a primary data source that defines the existence of the instance with a primary table, and auxiliary data sources that can be used to add properties in the same database or a different one. When a declarative query mixes properties from more than one data source, the results are joined in memory.
(TODO: join queries not yet implemented... the main use case here uses an 'id' property and can leverage the 'matching' code for the in-memory data store to filter the results after running the queries separately. Will pick one NoSQL and one secrets DB for primary support but build it around a generic 'REST' adapter so it can be easily extended to augment the primary SQL store).
Memory data source
It's possible to use many of the capabilities of without a database. When the dbDisabled flag set to true uses an in-memory database.
It's also possible to turn off writes to the database - so changes are kept in memory and merged to produce the same results as if they were persisted until the application is restarted. This mode allows tests to be run against the production database without affecting production, or stage changes before a 'save' to DB.
Finally, a 'staging mode' allows changes to be stored in a local database that's transparently merged with the production DB. When the changes are ready tthey can be pushed to production. (TODO: work to be completed here as well)
 StrataCode
© 2020 Jeffrey Vroom
StrataCode
© 2020 Jeffrey Vroom